Keras examples-addition_rnn
1、任务描述
(1)任务概述:主要是利用序列学习来实现两个整数(字符串)的加法
(2)任务分析:两个整数相加,需要通过神经网络来训练,于是不能够直接将整型作为神经网络的输入;想想办法,如果将整数和加号等都转化为字符,于是就可以用一个字符串来表示这个加法问题了;字符串表示的加法问题,可以看成是文本,于是紧接着考虑用什么语言模型来表示这个问题,由于加法问题中涉及到的字符种类不多,只有12类,‘0-9’、‘+’、‘ ’,因此可以直接考虑使用one-hot模型。
2、具体实现
(1)引入相应的库
from __future__ import print_function
from keras.models import Sequential
from keras import layers
import numpy as np
from six.moves import range
from keras.utils import plot_model
(2)定义相应的方法、设置常量
这里主要定义了两个类,一个是编码解码类,另一个是预测结果的颜色处理类。
①编码解码类:包含三个方法:构造方法,编码方法,解码方法。
构造方法:在创建编码解码对象时,会接收一个字符串,这个字符串包含了所有涉及到的字符,构造函数利用该字符串创建了两个字典,一个是{字符:索引}型字典,一个是{索引:字符}型字典。前一个字典主要在编码阶段使用,用于将一个字符转化为one-hot类型,后裔字典主要在解码阶段使用,将one-hot矩阵表示的问题转化为对应的文本。
{字符:索引}型:{‘ ‘: 0, ‘+’: 1, ‘0’: 2, ‘1’: 3, ‘2’: 4, ‘3’: 5, ‘4’: 6, ‘5’: 7, ‘6’: 8, ‘7’: 9, ‘8’: 10, ‘9’: 11}
{索引,字符}型:{0: ‘ ‘, 1: ‘+’, 2: ‘0’, 3: ‘1’, 4: ‘2’, 5: ‘3’, 6: ‘4’, 7: ‘5’, 8: ‘6’, 9: ‘7’, 10: ‘8’, 11: ‘9’}
编码方法:将传来的一个字符串编码城one-hot矩阵,具体实现是首先创建一个零矩阵,然后针对字符串的第i个字符,得到这个字符在字符字典中的索引为j,于是将零矩阵的第i行和第j列的元素置为1。直到将这个字符串的所有字符都编码。
解码方法:解码方法可以看成是编码方法的逆,将one-hot矩阵转为字符串
其实,这个类也可以利用keras内置的文本预处理方法来实现。
②颜色处理类:主要声明一些常量。
class CharacterTable(object):
# 对于给定的一组字符
## 将他们编码为one-hot的整型来表示
## 将一个one-hot表示的解码为其字符
## 将概率向量解码为其字符输出
def __init__(self,chars):
# 初始化字符表
self.chars=sorted(set(chars))
# 创建字符表中字符和其索引的对应关系(字符:索引)
self.char_indices=dict((c,i) for i,c in enumerate(self.chars))
print(self.char_indices)
# 创建字符表中字符和其索引的对应关系(索引:字符)
self.indices_char=dict((i,c) for i,c in enumerate(self.chars))
print(self.indices_char)
# 将给定的字符串C编码成one-hot模型,参数num_rows指定这个矩阵的行数(等于问题的最大长度),列数等于字符表中总的字符数
def encode(self,c,num_rows):
# 创建一个零矩阵,行数为问题的最大长度,列数等于字符表中总的字符数
x=np.zeros((num_rows,len(self.chars)))
# 针对问题字符串中的第i个字符
for i,c in enumerate(c):
# 将0矩阵的第i行和字符索引列的元素设置为1
x[i,self.char_indices[c]]=1
# 返回对字符串编码后的矩阵
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = x.argmax(axis=-1)
return ''.join(self.indices_char[x] for x in x)
class colors:
ok = '\033[92m'
fail = '\033[91m'
close = '\033[0m'
# 设置训练集大小
TRAINING_SIZE=50000
# 设置加数的最大位数
DIGITS=3
# 是否逆序
REVERSE=True
# 问题的最大长度
MAXLEN=DIGITS+1+DIGITS
# 所有字符
chars="0123456789+ "
# 创建字符表对象
ctable=CharacterTable(chars)
{' ': 0, '+': 1, '0': 2, '1': 3, '2': 4, '3': 5, '4': 6, '5': 7, '6': 8, '7': 9, '8': 10, '9': 11}
{0: ' ', 1: '+', 2: '0', 3: '1', 4: '2', 5: '3', 6: '4', 7: '5', 8: '6', 9: '7', 10: '8', 11: '9'}
(3)构造训练数据
训练数据我们通过随机产生的整数来构造问题,通过整数相加的得到问题的答案,接着将问题和答案都字符化,并分别将每个问题和答案都用空格来填充至固定大小。最终问题的格式为:”——45+0”,答案的格式为:”54—“(“—”表示空格,这里已经将问题前后逆转了)。具体见下面代码。
questions=[]
expected=[]
seen=set()
print("Generating data...")
while len(questions) < TRAINING_SIZE:
# ——————————————————————————————————————
# np.random.choice
# 参数意思分别是从给定的候选集中以概率P随机选择, p没有指定的时候相当于是一致的分布,replacement决定是否放回,size决定选择的个数
# randint是在[1,4)之间随机产生一个整数,这个整数决定此次产生的字符串的长度,然后依次随机从0-9中选择一个数字,最后拼接起来
# ——————————————————————————————————————
f=lambda: int("".join(np.random.choice(list("0123456789")) for i in range(np.random.randint(1,DIGITS+1))))
a,b=f(),f()
# 将随机选择的两个整数排序
key=tuple(sorted((a,b)))
# 如果此次选择的加法问题已经存在了,则忽略
if key in seen:
continue
seen.add(key)
# 构造问题,组装成a+b的字符串
q="{}+{}".format(a,b)
# 用空格来填充问题成预设的最大长度
query=q+" "*(MAXLEN-len(q))
# 构造问题的答案
ans=str(a+b)
# 用空格来填充答案,使其长度为4
ans+=" "*(DIGITS+1-len(ans))
# 如果需要逆序
if REVERSE:
query=query[::-1]
# 将构造的问题和答案加入相应的列表
questions.append(query)
expected.append(ans)
print('Total addition questions:', len(questions))
Generating data...
Total addition questions: 50000
(4)将训练数据向量化
这一部分就是调用预先写好的编码解码类来将问题和答案转化为one-hot模型。
print("Vectorization...")
# 将x初始化为(样本数,每个问题的最大长度,总的字符数)的布尔型矩阵
x=np.zeros((len(questions),MAXLEN,len(chars)),dtype=np.bool)
y=np.zeros((len(questions),DIGITS+1,len(chars)),dtype=np.bool)
# 针对训练问题集中的每一个问题,对其进行编码,one-hot模型,一个问题编码后对应一个矩阵
for i,sentence in enumerate(questions):
x[i]=ctable.encode(sentence,MAXLEN)
for i,sentence in enumerate(expected):
y[i]=ctable.encode(sentence,DIGITS+1)
Vectorization...
(5)将训练集随机化
indices=np.arange(len(y))
np.random.shuffle(indices)
x=x[indices]
y=y[indices]
(6)划分训练集和测试集
split_at=len(x)-len(x)//10
(x_train,x_val)=x[:split_at],x[split_at:]
(y_train,y_val)=y[:split_at],y[split_at:]
# 查看训练集和验证集数据信息
print("Training Data:")
print(x_train.shape)
print(y_train.shape)
print("Validation Data:")
print(x_val.shape)
print(y_val.shape)
Training Data:
(45000, 7, 12)
(45000, 4, 12)
Validation Data:
(5000, 7, 12)
(5000, 4, 12)
(7)搭建网络结构
网络结构通过keras的序列模型搭建起来,其结构图如图所示: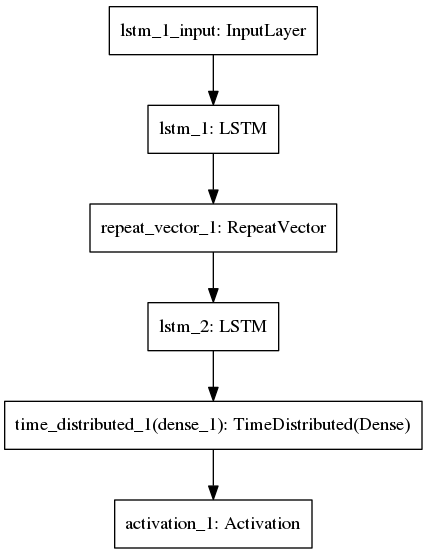
RNN=layers.LSTM
HIDDEN_SIZE=128
BATCH_SIZE=128
LAYERS=1
print("Building model...")
model=Sequential()
model.add(RNN(HIDDEN_SIZE,input_shape=(MAXLEN,len(chars))))
model.add(layers.core.RepeatVector(DIGITS+1))
# 创建LAYERS层的RNN网络层
for _ in range(LAYERS):
model.add(RNN(HIDDEN_SIZE,return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars))))
model.add(layers.Activation("softmax"))
model.compile(loss="categorical_crossentropy",optimizer="adam",metrics=['accuracy'])
model.summary()
Building model...
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 128) 72192
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 4, 128) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 4, 128) 131584
_________________________________________________________________
time_distributed_1 (TimeDist (None, 4, 12) 1548
_________________________________________________________________
activation_1 (Activation) (None, 4, 12) 0
=================================================================
Total params: 205,324
Trainable params: 205,324
Non-trainable params: 0
_________________________________________________________________
其中,部分API的功能介绍如下:
①keras.layers.core.RepeatVector(n):将输入重复n次
参数n:整数,重复的次数
输入shape:形如(nb_samples, features)的2D张量
输出shape:形如(nb_samples, n, features)的3D张量
②keras.layers.wrappers.TimeDistributed(layer):该包装器可以把一个层应用到输入的每一个时间步上,这个有点难理解,在网上找到了一篇通俗易懂的解释,看了好半天才才理解到(智商是硬伤)。地址:https://blog.csdn.net/u012193416/article/details/79477220
(8)训练和预测
# train the model each generation and show predictions against the validataion dataset
for iteration in range(1,200):
print()
print("-"*50)
print("Iteration",iteration)
model.fit(x_train,y_train,batch_size=BATCH_SIZE,epochs=1,validation_data=(x_val,y_val))
--------------------------------------------------
Iteration 1
Train on 45000 samples, validate on 5000 samples
Epoch 1/1
45000/45000 [==============================] - 7s 148us/step - loss: 1.8855 - acc: 0.3222 - val_loss: 1.8006 - val_acc: 0.3410
.........
--------------------------------------------------
Iteration 199
Train on 45000 samples, validate on 5000 samples
Epoch 1/1
45000/45000 [==============================] - 6s 136us/step - loss: 0.0014 - acc: 0.9997 - val_loss: 0.0027 - val_acc: 0.9991
上面就是使用处理好的数据来训练网络的过程,一共训练200轮(不知道是否理解有误),这段代码与下面这句代码等效:
model.fit(x_train,y_train,batch_size=BATCH_SIZE,epochs=200,validation_data=(x_val,y_val))
接下来就是测试模型的性能了,从验证集里随机产生10个问题,通过模型得到预测的答案,
# select 10 samples from the validation set at random so we can see errors
for i in range(10):
# 从验证集数据的索引范围内随机产生一个索引
ind=np.random.randint(0,len(x_val))
# 通过索引,获取问题的内容和问题答案
rowx,rowy=x_val[np.array([ind])],y_val[np.array([ind])]
# 通过模型预测答案
preds=model.predict_classes(rowx,verbose=0)
# 将问题解码
q=ctable.decode(rowx[0])
# 将答案解码
correct=ctable.decode(rowy[0])
# 将预测的结果解码
guess=ctable.decode(preds[0],calc_argmax=False)
# 构造输出格式
print("Q:",q[::-1] if REVERSE else q,end=" ")
print('T:',correct,end=" ")
# 根据是否正确选择不同的输出格式
if correct == guess:
print(colors.ok + '☑' + colors.close, end=' ')
else:
print(colors.fail + '☒' + colors.close, end=' ')
print(guess)
Q: 948+50 T: 998 [92m☑[0m Q: 324+89 T: 413 [92m☑[0m Q: 50+424 T: 474 [92m☑[0m Q: 910+2 T: 912 [92m☑[0m Q: 15+157 T: 172 [92m☑[0m Q: 660+0 T: 660 [92m☑[0m Q: 453+32 T: 485 [92m☑[0m Q: 4+263 T: 267 [92m☑[0m Q: 6+424 T: 430 [92m☑[0m Q: 92+942 T: 1034 [92m☑[0m
# model.fit(x_train,y_train,batch_size=BATCH_SIZE,epochs=200,validation_data=(x_val,y_val))
(9)网络结构可视化
plot_model(model, to_file='addition_rnn_model.png')
3、小结
通过这一次实验,收获肯定是有的。首先是将一个实际问题转化为网络结构能过处理的一个问题。转化为什么问题,采用什么模型来解,这些都是很重要的;接着就是数据的构造、one-hot模型的实现,虽然以前也手写代码实现过one-hot模型,但是这次通过自己构造数据,然后不通过接口来将数据转化为one-hot模型,这是第一次遇到,因此学会了这种情况的处理方式。最后就是keras的一些层的使用,比如说RepeatVector()和TimeDistributed(),由于才开始学keras,看了文档没多久就忘记了,即使不忘,有些层也只知道个大概,具体怎么用还是不清楚。通过这个例子,里面涉及到了这两个层,然后我也去查了这两个层的资料,至少现在知道了是怎么使用的。那这一篇就这样吧!



